
Turning Coding Tasks into Feedback Loops

One of the AI coding techniques I’ve found most useful is turning tasks into feedback loops. This often involves organizing the task into the following components:
A verification method: This could be getting the code to pass a build, a test, an MCP tool the agent can use to fetch results, or some form of consistency check. The verification method must provide feedback or data that allows the model to infer success or failure.
The Loop Instruction: Explicitly instruct the agent to investigate and iterate on the task until it passes the verification. (Note: While many coding agents handle this automatically, explicit framing often improves reliability).
A Couple of Examples
Here are a few examples of how I used this technique recently.
Making UI Changes
This is one of my favorite use cases. In this scenario, the verification can sometimes be as vague as “make sure the UI renders well on both desktop and mobile, and use Playwright to verify.”
Current LLMs are trained to distinguish bad UX from good UX to some extent, and this is often enough to make progress. The agent will launch Playwright via MCP, capture a screenshot, and verify the UI visual output itself.
Debugging Queue Status
I was working on a long-running, multi-step flow where a service enqueues tasks and multiple workers dequeue them to update a database. The flow could run for 5 to 20 minutes. I encountered bugs with the progress display on the UI, which polls data from both the queue and the database.
I asked the agent to monitor the queue by running a background command to save logs into a file, and then query the database every 30 seconds to verify that the logs and database updates matched expectations. It was able to locate the bug, figure out the root cause, and propose a fix based on the discrepancies it observed.
Why it Works
Most coding agents run on a ReAct loop. This consists of:
Thinking: Reasoning about what to do next with the task. If the task is completed, it decides to stop.
Acting: Reading/writing/updating code or calling tools like search, MCP, etc.
Observing: Reviewing the results from the code changes or tools, then returning to the “Thinking” step.
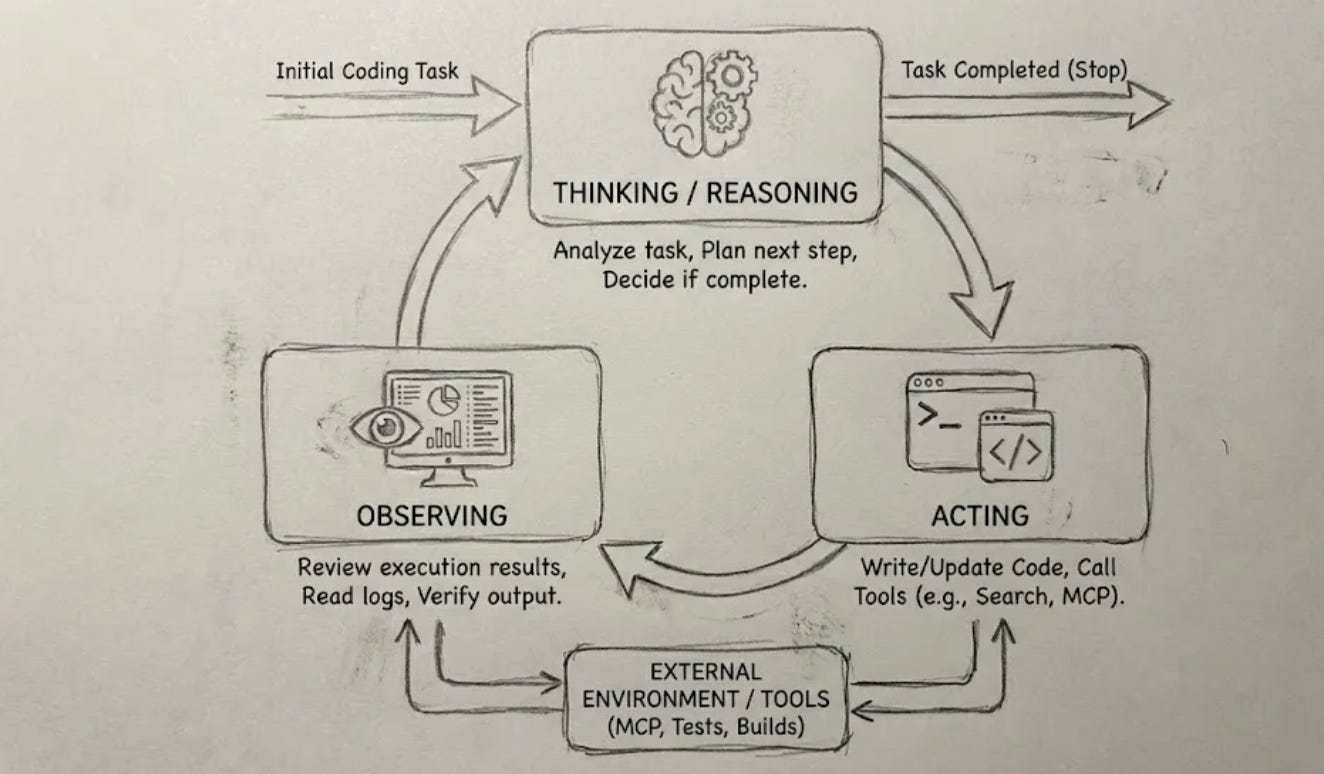
While real coding agents are often more complex—like the OpenAI Codex agent loop—the core idea remains the same.
Because agents are built to observe the results of their actions, we can leverage this behavior. For a task like “fix bug X,” the agent can analyze existing code, make changes, and reason about whether those changes worked.
If we provide the agent with a mechanism for feedback—such as a unit test (we can even ask it to write the reproduction test first), a way to capture logs, or an MCP tool to verify changes—it can observe the precise effects of its code. This allows it to reason much more effectively.
This is similar to how we software engineers work. I can’t recall how many times I thought I had fixed a bug, only to test it and realize I hadn’t. Coding agents, just like us, think better when they have verification tools.